その1:GI構築編
その2:MySQL構築編
その3:機能確認編
はじめに
前回の記事でベースの環境構築は済みましたので、いよいよ高可用性の機能を確認していきます。
1. 高可用性の機能確認
接続確認用の準備
HAの切り替わりを確認するために準備をしておきます。
- 接続ユーザーの作成
1# mysql -uroot -p --socket=/u02/app/mysql/datastore/instance1/tmp/mysql.sock -e "CREATE USER 'test'@'%' IDENTIFIED BY 'Mysql8.0';"
- Application VIP ホスト名を hosts ファイルに追記
123456[node1,2]# vi /etc/hosts# Application VIP## mysql instance1192.168.100.40 mysql-instance1-vip
リソース再配置(relocate)
node1,node2 ともにOSは通常稼働中の状態で、node1 → node2 へ稼働系を切り替えてみます。
切り替え前の状態を確認します。node1で MySQL instance1 が稼働中です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE -------------------------------------------------------------------------------- # /u01/app/xag/bin/agctl status mysql_server instance1 Mysql Server instance 'instance1' is running on node1 # mysql -utest -p -h mysql-instance1-vip -e "SHOW VARIABLES LIKE 'hostname';" Enter password: +---------------+-------+ | Variable_name | Value | +---------------+-------+ | hostname | node1 | +---------------+-------+ |
agctl relocate コマンドでリソースを再配置させます。
|
1 |
# /u01/app/xag/bin/agctl relocate mysql_server instance1 |
instance1 用の Application VIP も共連れで node2 へ移動していることが確認できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node2 STABLE xag.instance1.mysql 1 ONLINE ONLINE node2 STABLE -------------------------------------------------------------------------------- # /u01/app/xag/bin/agctl status mysql_server instance1 Mysql Server instance 'instance1' is running on node2 # mysql -utest -p -h mysql-instance1-vip -e "SHOW VARIABLES LIKE 'hostname';" Enter password: +---------------+-------+ | Variable_name | Value | +---------------+-------+ | hostname | node2 | +---------------+-------+ |
node1 に切り戻してみます。
併せて実行時間も測ってみたところ、この環境では13秒程度で relocate されました。
|
1 2 3 4 5 |
# time /u01/app/xag/bin/agctl relocate mysql_server instance1 real 0m13.056s user 0m0.418s sys 0m0.212s |
mysqld プロセスダウン時
mysqldプロセスが異常終了によりダウンした場合、Oracle Clusterware の機能ではなく、systemd サービス(RPMインストール時)またはmysqld_safe(Tar ballインストール時)によって自動再起動されます。
※例えば、systemd 管理の場合、mysqld@.service の設定で Restart=on-failure となっているので0以外の終了コードで停止した場合、自動で再起動されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE -------------------------------------------------------------------------------- # pgrep -al mysqld 9473 /usr/sbin/mysqld --defaults-file=/u02/app/mysql/datastore/instance1/my.cnf --defaults-group-suffix=@instance1 --pid-file=/u02/app/mysql/datastore/instance1/mysqld_instance1.pid # kill -9 9473 # pgrep -al mysqld <--★別プロセスとして起動された 19867 /usr/sbin/mysqld --defaults-file=/u02/app/mysql/datastore/instance1/my.cnf --defaults-group-suffix=@instance1 --pid-file=/u02/app/mysql/datastore/instance1/mysqld_instance1.pid # /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE -------------------------------------------------------------------------------- ★node2へはフェイルオーバーしていない |
ちなみに、Clusterware がリソースを再起動したかどうかは以下のコマンドで確認できます。
今回はRESTART_COUNTが0なので Clusterwareによる再起動ではありません。
|
1 2 |
# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1.mysql -v | grep RESTART_COUNT RESTART_COUNT=0 |
mysqld プロセスハング時
プロセスが応答不能になった場合の死活監視と保護について挙動を確認してみます。
その前に、Oracle Clusterware はどのようにリソース監視を行っているのかといいますと、、、
まず前提として、Clusterware リソースにはリソース属性というパラメーターが存在します。
基本的なものから詳細なものまで様々なリソース属性がありますが、リソースの死活監視の挙動は以下のパラメーターが関係してきます。
※リソース属性の各説明文章はClusterware管理およびデプロイメント・ガイドより引用
| リソース属性 | 説明 | XAG Agent mysql_server のデフォルト値 |
|---|---|---|
| CHECK_INTERVAL | checkアクションの実行を繰り返す時間間隔(秒単位)。間隔を短くするとより頻繁にチェックできますが、スクリプト・エージェントを使用するとリソースの消費も増大します。リソースの消費を低減するには、アプリケーション固有のエージェントを使用します。 | 30 |
| CHECK_TIMEOUT | チェック・アクションを実行できる最大時間(秒単位)。アクションが指定された時間内に完了しなかった場合、Oracle Clusterwareはエラー・メッセージを戻します。この属性が指定されていない場合または0秒が指定されている場合、Oracle ClusterwareはSCRIPT_TIMEOUT属性の値を使用します。 | 0 |
| SCRIPT_TIMEOUT | アクションを実行する最大時間(秒単位)。アクション・スクリプトが指定された時間内に完了しなかった場合、Oracle Clusterwareはエラー・メッセージを戻します。このタイムアウトは、すべてのアクション(start、stop、checkおよびclean)に適用されます。 | 60 |
| FAILURE_INTERVAL | リソースがFAILURE_THRESHOLD属性で指定した障害の回数を超えた場合にOracle Clusterwareがリソースを停止するまでの間隔(秒単位)。 | 600 |
| FAILURE_THRESHOLD | リソースに指定されたFAILURE_INTERVAL内で検出される障害の数で、この値を超えると、Oracle Clusterwareがリソースを使用不可としてマーク付けし、そのリソースの監視を停止します。指定した回数の障害がリソースで発生すると、Oracle Clusterwareはそのリソースを停止します。 | 5 |
| RESTART_ATTEMPTS | Oracle Clusterwareが、リソースの再配置を試行する前に、リソースの現行のサーバー上でリソースの再起動を試行する回数。1の値を指定した場合、Oracle Clusterwareはサーバー上でリソースの再起動を1回のみ試行します。2回失敗すると、Oracle Clusterwareの再配置が試行されます。 | 5 |
| UPTIME_THRESHOLD | UPTIME_THRESHOLDの値は、Oracle Clusterwareがリソースが安定しているとみなすまでに、リソースが稼働中である必要がある時間の長さを表します。UPTIME_THRESHOLD属性の値を設定すると、リソースの安定性を示すことができます。 この属性の値は、数値の後に秒(s)、分(m)、時間(h)、日(d)または週(w)を示す文字を付けて入力します。たとえば、7hという値は、稼働時間のしきい値が7時間であることを示します。 Oracle Clusterwareは、UPTIME_THRESHOLDに指定した時間が経過すると、停止、起動、再配置または障害のようなリソース状態が変更されるイベントが次に発生したときに、RESTART_COUNTの値を0にリセットします。RESTART_COUNTの値がRESTART_ATTEMPTSに設定した値に達すると、Oracle Clusterwareはアラートを生成します。カウンタは、次回リソースの障害発生時や再起動時に、効果的にリセットされます。しきい値は、再起動がカウントされて破棄される時間の長さを示しています。しきい値に達してリソースが失敗すると、再起動されます。 |
10m |
実際に確認するコマンドは以下になります。(全パラメーターが出力されるので egrep で表示を絞っています)
|
1 2 3 4 5 6 7 8 |
# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1.mysql -f | egrep 'CHECK_INTERVAL|SCRIPT_TIMEOUT|FAILURE_INTERVAL|FAILURE_THRESHOLD|RESTART_ATTEMPTS|UPTIME_THRESHOLD' CHECK_INTERVAL=30 FAILURE_INTERVAL=600 FAILURE_THRESHOLD=5 OFFLINE_CHECK_INTERVAL=0 RESTART_ATTEMPTS=5 SCRIPT_TIMEOUT=60 UPTIME_THRESHOLD=10m |
リソースの死活監視の仕組みは要約すると以下のような動きになります。
- CHECK_INTERVAL秒間隔でリソースのチェック・アクションを実行する。
- systemd サービス管理の場合は、
systemctl status mysqld - mysqld_safe からの起動の場合は、
mysqladmin status
- systemd サービス管理の場合は、
- リソースチェックに失敗する、または(CHECK_TIMEOUT=0なので)SCRIPT_TIMEOUT秒以内に完了しなかった場合、リソースの再起動を試みる。
- RESTART_COUNT 数が RESTART_ATTEMPTS を超え、かつ FAILURE_COUNT数 が FAILURE_INTERVAL 期間内で FAILURE_THRESHOLD 数以内の場合、フェイルオーバーを実行する。
- FAILURE_COUNT数 が FAILURE_INTERVAL 期間内で FAILURE_THRESHOLD 数を超えた場合、リソースは OFFLINEとなる(クラスター内で完全に停止される)
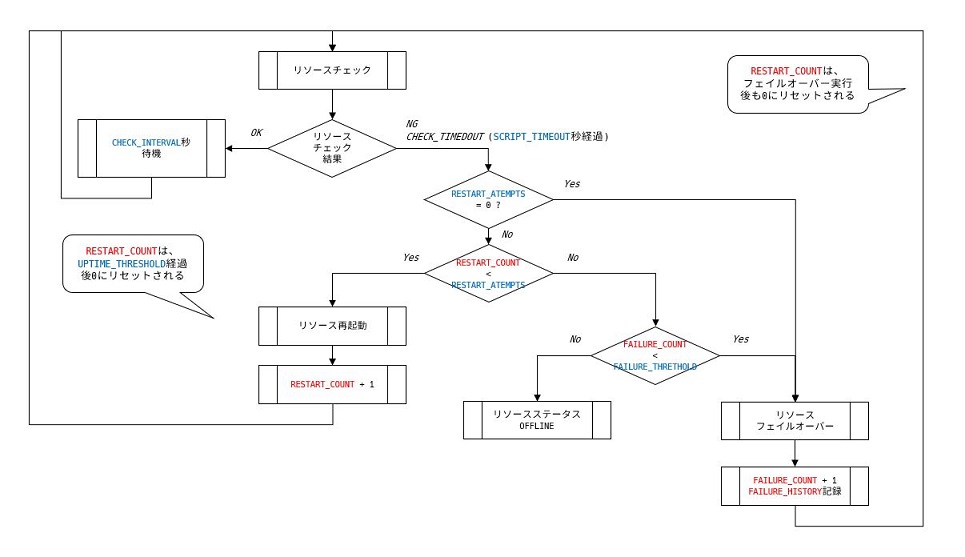
それでは、実際にリソースチェックの失敗を発生させ、挙動を確認してみます。
リソースチェック失敗による再起動回数が閾値を超過した場合、Clusterware アラートログ($ORACLE_BASE/diag/crs/<ホスト名>/crs/trace/alert.log)に以下のメッセージが出力されます。
|
1 |
2019-10-31 12:01:06.775 [CRSD(6051)]CRS-2771: Maximum restart attempts reached for resource 'xag.instance1.mysql'; will not restart. |
リソース属性値の遷移を観察していると、確かに設定値に準じてフェイルオーバーが発生したことが確認できました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# while(true);do LANG=C date;/u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1.mysql -v | egrep -v 'NAME|TYPE|CARDINALITY_ID|OXR_SECTION|ID|RESOURCE_GROUP|INSTANCE_COUNT';sleep 10;done : Thu Oct 31 12:01:05 JST 2019 LAST_SERVER=node1 STATE=ONLINE on node1 TARGET=ONLINE RESTART_COUNT=5 ★リソース再起動回数が閾値(RESTART_ATTEMPTS)に到達 FAILURE_COUNT=0 FAILURE_HISTORY= INCARNATION=7 LAST_RESTART=10/31/2019 12:00:03 LAST_STATE_CHANGE=10/31/2019 12:00:03 STATE_DETAILS= INTERNAL_STATE=STABLE TARGET_SERVER=node1 ★ここでリソースチェック失敗を発生させる Thu Oct 31 12:01:15 JST 2019 LAST_SERVER=node1 STATE=OFFLINE TARGET=ONLINE RESTART_COUNT=0 ★リソース再起動回数カウンタリセット FAILURE_COUNT=1 ★障害発生回数カウントアップ FAILURE_HISTORY=1572490866:node1 ★障害履歴として記録された INCARNATION=7 LAST_RESTART=10/31/2019 12:01:08 LAST_STATE_CHANGE=10/31/2019 12:01:06 STATE_DETAILS= INTERNAL_STATE=STARTING ★node2へ TARGET_SERVER=node2 ★フェイルオーバー実行 : |
XAG Agentのリソース属性値は、agctl modify コマンドの--attributeパラメーターを使用することで任意の値に変更することができます。もちろん、リソース登録時に指定することもできますので、デフォルトから変更するのであれば、予めプロセス死活監視方針を定めた上で最初に設定しておいて、テストで調整していくのがよいでしょう。
|
1 |
$ agctl modify mysql_server instance1 --attribute "CHECK_INTERVAL=60,FAILURE_INTERVAL=30" |
※なお、oraから始まるクラスターリソースのリソース属性値はOracleサポートからの指示がない限りユーザーが変更することはできませんのでご注意ください。(変更した場合サポート対象外となります)
mysqld に対する人的な起動停止オペレーションミス
以下のシチュエーションはどちらかと障害というより運用者が誤操作してしまったような場合の挙動確認になります。
- node1 で起動中の MySQL クラスターリソースを node2 で起動させようとした場合
⇒XAG Agent が起動状態を確認し、二重起動が抑止されました。12345[node2]$ /u01/app/xag/bin/agctl status mysql_server instance1Mysql Server instance 'instance1' is running on node1$ /u01/app/xag/bin/agctl start mysql_server instance1XAG-216: Instance 'instance1' is already running. - agctl コマンドで起動した MySQL クラスターリソースのプロセスを、systemctl コマンドで停止した場合
⇒今度は Clusterware がOFFLINEを検知し、自動再起動によって復旧されます。
クラスター管理下での完全な正常停止は、agctl stopコマンドを利用することになります。123456789# /u01/app/xag/bin/agctl status mysql_server instance1Mysql Server instance 'instance1' is running on node1# systemctl stop mysqld@instance1# /u01/app/xag/bin/agctl status mysql_server instance1Mysql Server instance 'instance1' is not running <--★プロセス停止を認識# /u01/app/xag/bin/agctl status mysql_server instance1Mysql Server instance 'instance1' is running on node1 <--★直後に起動状態になっている# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1.mysql -v | grep RESTART_COUNTRESTART_COUNT=1 <--★再起動カウンタが上がっている
正系サーバーダウン時
アクティブ・スタンバイHAの基本機能となりますが、当然ながら副系(node2)へフェイルオーバーすることを確認しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
$ ssh root@node1 '/u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t' -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE -------------------------------------------------------------------------------- $ vagrant halt node1 ==> node1: Halting domain... $ ssh root@node2 '/u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t' -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node2 STABLE xag.instance1.mysql 1 ONLINE ONLINE node2 STABLE -------------------------------------------------------------------------------- |
再び node1 を起動させた後も、MySQL クラスターリソースは node1 へは戻らずそのまま node2 で稼働しています。node1のダウンや故障となる原因を取り除いた後、リソースを正系へ切り戻す流れとなります。
副系サーバーダウン時
node1 で MySQL が稼働中に node2 をサーバーダウンしても、クラスターリソースの稼働には影響を与えないことが確認できました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
$ ssh root@node1 '/u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t' -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE -------------------------------------------------------------------------------- $ vagrant halt node2 ==> node2: Halting domain... $ ssh root@node1 '/u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t' -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE -------------------------------------------------------------------------------- |
NIC障害時
- Public Network 通信不可
node1 で Application VIP が稼働している Public Network の NIC をダウンさせてみます。12345678910# ip a show dev eth13: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 52:54:00:ee:ff:02 brd ff:ff:ff:ff:ff:ffinet 192.168.100.11/24 brd 192.168.100.255 scope global eth1valid_lft forever preferred_lft foreverinet 192.168.100.40/24 brd 192.168.100.255 scope global secondary eth1:1valid_lft forever preferred_lft foreverinet6 fe80::5054:ff:feee:ff02/64 scope linkvalid_lft forever preferred_lft forever# ip l set eth1 downApplication VIP と共に MySQL クラスターリソースがnode2へフェイルオーバーしました。
123456789101112131415161718# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{-vip.vip,.mysql} -t--------------------------------------------------------------------------------Name Target State Server State details--------------------------------------------------------------------------------Cluster Resources--------------------------------------------------------------------------------xag.instance1-vip.vip1 ONLINE ONLINE node2 STABLExag.instance1.mysql1 ONLINE ONLINE node2 STABLE--------------------------------------------------------------------------------# mysql -utest -p -h mysql-instance1-vip -e "SHOW VARIABLES LIKE 'hostname';"Enter password:+---------------+-------+| Variable_name | Value |+---------------+-------+| hostname | node2 |+---------------+-------+ - Private Network 通信不可
次は、Clusterware の稼働上重要な通信を行っている Private Network の NIC をダウンさせてみます。(node1)12345678910# ip a show dev eth24: eth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 52:54:00:38:41:28 brd ff:ff:ff:ff:ff:ffinet 192.168.200.11/24 brd 192.168.200.255 scope global eth2valid_lft forever preferred_lft foreverinet 169.254.11.46/19 brd 169.254.31.255 scope global eth2:1valid_lft forever preferred_lft foreverinet6 fe80::5054:ff:fe38:4128/64 scope linkvalid_lft forever preferred_lft forever# ip l set eth2 down※
169.254.11.46/19(eth2:1)という仮想IPアドレスについては後述します。NICダウン後、程無くしてNode1の Clusterwareの主要スタックが Oracle High Availability Services 以外異常な状態になります。
12345# /u01/app/19.0.0/grid/bin/crsctl check crsCRS-4638: Oracle High Availability Services is onlineCRS-4535: Cannot communicate with Cluster Ready ServicesCRS-4530: Communications failure contacting Cluster Synchronization Services daemonCRS-4534: Cannot communicate with Event Managerスプリットブレイン防止のため、クラスターから node1 が切り離され、生存する他のクラスターメンバーノードへリソースがフェイルオーバーされました。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263# /u01/app/19.0.0/grid/bin/crsctl stat res -t--------------------------------------------------------------------------------Name Target State Server State details--------------------------------------------------------------------------------Local Resources--------------------------------------------------------------------------------ora.DATA.ACFSVOL01.advmONLINE ONLINE node2 STABLEora.DATA.ACFSVOL02.advmONLINE ONLINE node2 STABLEora.LISTENER.lsnrONLINE ONLINE node2 STABLEora.chadONLINE ONLINE node2 STABLEora.data.acfsvol01.acfsONLINE ONLINE node2 mounted on /u02/app/mysql/product,STABLEora.data.acfsvol02.acfsONLINE ONLINE node2 mounted on /u02/app/mysql/datastore/instance1,STABLEora.net1.networkONLINE ONLINE node2 STABLEora.onsONLINE ONLINE node2 STABLEora.proxy_advmONLINE ONLINE node2 STABLE--------------------------------------------------------------------------------Cluster Resources--------------------------------------------------------------------------------ora.ASMNET1LSNR_ASM.lsnr(ora.asmgroup)1 ONLINE OFFLINE STABLE2 ONLINE ONLINE node2 STABLE3 ONLINE OFFLINE STABLEora.DATA.dg(ora.asmgroup)1 ONLINE OFFLINE STABLE2 ONLINE ONLINE node2 STABLE3 OFFLINE OFFLINE STABLEora.LISTENER_SCAN1.lsnr1 ONLINE ONLINE node2 STABLEora.asm(ora.asmgroup)1 ONLINE OFFLINE STABLE2 ONLINE ONLINE node2 Started,STABLE3 OFFLINE OFFLINE STABLEora.asmnet1.asmnetwork(ora.asmgroup)1 ONLINE OFFLINE STABLE2 ONLINE ONLINE node2 STABLE3 OFFLINE OFFLINE STABLEora.cvu1 ONLINE ONLINE node2 STABLEora.node1.vip1 ONLINE OFFLINE STABLEora.node2.vip1 ONLINE ONLINE node2 STABLEora.qosmserver1 ONLINE ONLINE node2 STABLEora.scan1.vip1 ONLINE ONLINE node2 STABLExag.instance1-vip.vip1 ONLINE ONLINE node2 STABLExag.instance1.mysql1 ONLINE ONLINE node2 STABLE--------------------------------------------------------------------------------このように、Private Networkの通信ができなくなることは、Clusterwareにとって甚大な影響となります。
今回の環境では Private Network は単一の NIC で構成していますが、本番環境では必然的に冗長化することになります。
冗長化は一般的なボンディング以外に、GI では冗長インターコネクトという構成方法があります。
これは、Private Network用に2~4つのそれぞれ別のネットワークセグメントに属するNICを用いて、GIが内部的に付与する高可用性IP(HAIP)が、障害時に自動的に着け替えわれる仕組みとなっています。
詳細についてはマニュアルや少しバージョンは古いですがこのあたりの資料(P.87-99)をご一読いただけると理解が深まるかと思います。前出の169.254.11.46/19(eth2:1)という仮想IPアドレスはこの冗長インターコネクトで利用するHAIPになります。
※残念ながら、単一NICではHAIPはインストール時に付与されるだけで、実際には機能しません。
ACFS リソース停止
その2:MySQL構築編にて、agctl add mysql_server コマンドでクラスターリソースに登録する際に、--filesystems という任意のパラメーターがあり起動停止の依存関係を設定できる、と補足していました。
(6)の–filesystemsパラメーターについては、インスタンスが使用するデータディレクトリの ACFS リソース名を指定すると、起動・停止の依存関係を組むことができます。これについては次回検証したいと思います。
実は、このパラメーターは本構成ではこの依存関係の設定を入れておかないとOS再起動時に問題になってしまうのです。
理由としては以下の通りで、
- GI のデーモンプロセス(スタック)には起動順序があり、定められた依存関係に準じて起動していきます。
- ASMとそれに紐づくADVM,ACFS の起動時間は他の GI リソースよりも長く、ほとんどの場合起動完了するのが最後になります。
- OSをクリーンな状態から起動させた場合、MySQL のクラスターリソースは、ACFS の起動完了を待たずに mysqld プロセスを起動させようとします。
ところが、ACFSが起動していないため、共有ディスク上の my.cnf や datadir にアクセスできず起動失敗となります。
「MySQL が起動する前に ACFS が起動していること」は必須であるため、適切に依存関係を設定しておく必要があります。
ということで、agctl modify コマンドでACFSとの起動停止依存関係を設定します。
|
1 |
$ agctl modify mysql_server instance1 --filesystems ora.data.acfsvol02.acfs |
agctl config コマンドで設定が反映されていることを確認します。
|
1 2 3 4 5 |
$ agctl config mysql_server instance1 : File System resources needed: ora.data.acfsvol02.acfs : |
正しく設定できたので、ACFSリソース停止時の挙動を確認してみます。
ACFリソース ora.data.acfsvol02.acfs は node1,node2 で起動していますので、
試しに、node1のACFSリソースを単独で停止しようとすると、依存関係により抑制されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# /u01/app/19.0.0/grid/bin/crsctl stat res ora.data.acfsvol02.acfs -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Local Resources -------------------------------------------------------------------------------- ora.data.acfsvol02.acfs ONLINE ONLINE node1 mounted on /u02/app/ mysql/datastore/inst ance1,STABLE ONLINE ONLINE node2 mounted on /u02/app/ mysql/datastore/inst ance1,STABLE -------------------------------------------------------------------------------- # /u01/app/19.0.0/grid/bin/srvctl stop filesystem -d /dev/asm/acfsvol02-122 -node node1 PRCR-1014 : リソースora.data.acfsvol02.acfsの停止に失敗しました PRCR-1065 : リソースora.data.acfsvol02.acfsの停止に失敗しました CRS-2974: unable to act on resource 'ora.data.acfsvol02.acfs' on server 'node1' because that would require stopping or relocating resource 'xag.instance1.mysql' but the appropriate force flag was not specified |
-forceオプションを付与することで、MySQL インスタンスのリソースはnode2へrelocateされました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# /u01/app/19.0.0/grid/bin/srvctl stop filesystem -d /dev/asm/acfsvol02-122 -node node1 -force # /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance1{.mysql,-vip.vip} ora.data.acfsvol02.acfs -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Local Resources -------------------------------------------------------------------------------- ora.data.acfsvol02.acfs OFFLINE OFFLINE node1 volume /u02/app/mysq l/datastore/instance 1 is unmounted,STABL E ONLINE ONLINE node2 mounted on /u02/app/ mysql/datastore/inst ance1,STABLE -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node2 STABLE xag.instance1.mysql 1 ONLINE ONLINE node2 STABLE -------------------------------------------------------------------------------- |
※すべてのクラスターメンバーノードのACFSを停止すると、MySQLリソースも停止します。
2. 拡張性の機能確認
MySQLインスタンス追加
その1:GI構築編の手順を元に、インスタンス(instance2)を追加してみます。(ここでは注意点のみ記載し、詳細なコマンドは割愛します)
- ACFS ボリューム、ファイルシステム作成
- マウントポイント作成
- ACFS クラスターリソース登録、起動
- ACFS 上に 追加インスタンス用ディレクトリ作成
- my.cnf作成
インスタンス名とポート番号を変えます。12export INSTANCE_NAME=instance2export NUM_PORT=3307 - MySQL起動、初期設定(node1)
systemd 利用の場合、同じUnit定義ファイルを利用するので instance1 の時に実施したsystemctl edit mysqld@の手順は今回は不要ですが、instance2用のmy.cnfを一時的にsystemd環境変数に設定する手順は必要です。1234systemctl set-environment MYSQL_HOME="/u02/app/mysql/datastore/instance2"systemctl start mysqld@instance2systemctl unset-environment MYSQL_HOMEsystemctl restart mysqld@instance2 - MySQL起動(node2)
instance1 の時と同様に、初回起動時はデータ初期化不要のフラグを忘れず設定しておきます。1234echo "NO_INIT=true" > /etc/sysconfig/mysqlsystemctl start mysqld@instance2echo -n > /etc/sysconfig/mysqlsystemctl restart mysqld@instance2 - 追加インスタンスをクラスターリソースへ登録
Application VIPとAFCSリソースは追加インスタンス用の設定をセットするようにします。
systemd 利用版のリソース登録コマンド例)123456# /u01/app/xag/bin/agctl add mysql_server instance2 \--service_name mysqld@instance2 \--nodes node1,node2 \--network 1 --ip 192.168.100.41 \--filesystems ora.data.acfsvol03.acfs \--user grid --group oinstall - 追加インスタンス(クラスターリソース)起動
無事追加できました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance{1,2}{-vip.vip,.mysql} -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE xag.instance2-vip.vip <-★追加 1 ONLINE ONLINE node1 STABLE xag.instance2.mysql <-★追加 1 ONLINE ONLINE node1 STABLE -------------------------------------------------------------------------------- # df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 1.4G 20K 1.4G 1% /dev tmpfs 4.0G 845M 3.2G 21% /dev/shm tmpfs 1.4G 8.7M 1.4G 1% /run tmpfs 1.4G 0 1.4G 0% /sys/fs/cgroup /dev/mapper/vg_main-lv_root 32G 18G 15G 57% / /dev/sda1 497M 125M 373M 25% /boot tmpfs 274M 0 274M 0% /run/user/0 /dev/asm/acfsvol02-122 15G 4.1G 11G 28% /u02/app/mysql/datastore/instance1 /dev/asm/acfsvol01-122 5.0G 1.4G 3.7G 27% /u02/app/mysql/product /dev/asm/acfsvol03-122 5.0G 1.2G 3.9G 23% /u02/app/mysql/datastore/instance2 <-★追加 |
instance2 のみ副系へ relocate してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# /u01/app/xag/bin/agctl relocate mysql_server instance2 # /u01/app/19.0.0/grid/bin/crsctl stat res xag.instance{1,2}{-vip.vip,.mysql} -t -------------------------------------------------------------------------------- Name Target State Server State details -------------------------------------------------------------------------------- Cluster Resources -------------------------------------------------------------------------------- xag.instance1-vip.vip 1 ONLINE ONLINE node1 STABLE xag.instance1.mysql 1 ONLINE ONLINE node1 STABLE xag.instance2-vip.vip 1 ONLINE ONLINE node2 <-★ STABLE xag.instance2.mysql 1 ONLINE ONLINE node2 <-★ STABLE -------------------------------------------------------------------------------- |
ACFS ボリューム拡張
ACFS は、ADVM(ASM動的ボリューム・マネージャ)によって LVM のようにオンラインでボリュームサイズの変更(拡張、縮小)が可能です。
簡単な例ですが、instance1 用の ボリュームを5G増やしてみます。
ファイルシステムがマウント済みのボリュームサイズに対する変更は、acfsutil size コマンドを用います。(類似コマンドとして、asmcmd volresizeがありますが、このコマンドはマウント済みファイルシステムがある場合利用できません)
gridユーザーで実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 拡張前 $ /u01/app/19.0.0/grid/bin/asmcmd volinfo -G DATA ACFSVOL02 Diskgroup Name: DATA Volume Name: ACFSVOL02 Volume Device: /dev/asm/acfsvol02-122 State: ENABLED Size (MB): 10240 Resize Unit (MB): 64 Redundancy: MIRROR Stripe Columns: 8 Stripe Width (K): 1024 Usage: ACFS Mountpath: /u02/app/mysql/datastore/instance1 $ /sbin/acfsutil size +5G /u02/app/mysql/datastore/instance1 acfsutil size: new file system size: 16106127360 (15360MB) # 拡張後 $ /u01/app/19.0.0/grid/bin/asmcmd volinfo -G DATA ACFSVOL02 Diskgroup Name: DATA Volume Name: ACFSVOL02 Volume Device: /dev/asm/acfsvol02-122 State: ENABLED Size (MB): 15360 <== 5G拡張されている Resize Unit (MB): 64 Redundancy: MIRROR Stripe Columns: 8 Stripe Width (K): 1024 Usage: ACFS Mountpath: /u02/app/mysql/datastore/instance1 |
3. その他
XAG Agent ログファイル
/u01/app/xag/log/<ホスト名>ディレクトリに以下のログが出力されます。
| ログファイル名 | 内容 |
|---|---|
| agctl_<実行ユーザー名>.trc | agctl コマンド実行ログ |
| agctl_mysql_server_<実行ユーザー名>.trc | agctl コマンド実行ログ(対象:mysql_server) |
| <インスタンス名>_agent_mysql_server.trc | <インスタンス名>実行ログ |
| xagsetup_YY-MM-DD_hh-mi-ss.log | xagsetup.shによるinstall/deinstall実行時のログ |
<インスタンス名>_agent_mysql_server.trcは、デフォルトではCHECK_INTERVAL 30秒ごとに mysqladmin status でモニタリングするため、このトレースファイルに実行結果がロギングされ続け、ファイルサイズが増大していきます。
ただし、XAG Agent でログファイルサイズを監視しており、10MB 以上になると<インスタンス名>_agent_mysql_server_01.trcのように自動でログローテーションされ、10世代保管される仕様になっていますので、運用上も安心です。
XAG Agent 診断ログ収集スクリプト
公式リファレンスガイドに、XAG Agent の障害調査用として診断ログを収集する perl スクリプト xagdiagcollection.pl が紹介されていました。
スクリプトは $XAG_HOME 直下に置かれており、ラッパーシェルスクリプト xagdiagcollection.sh も併せて存在していました。(ラッパーシェルスクリプトについてはリファレンスガイドに記載なし)
試しに実行してみたところ、perlスクリプトにコードバグがありそのままでは動きませんでした、、、
(残念ながら本稿でコードは公開できませんのでご了承ください)
コードを読んでみたところと、このスクリプトの処理自体は、上述の/u01/app/xag/log/<ホスト名>ディレクトリ内のログを tar.gz で固めているものでしたので、現状は敢えて利用する必要性もあまりなさそうです。
このほか、GIのログ収集としては Oracleトレース・ファイル・アナライザ・コレクタ(TFA コレクター)を使うのがサポート調査用に有益です。
まとめ
- 全3回にわたって環境構築から機能確認までを行いました。
本記事では性能面での検証は行っておりませんが、アクティブ・スタンバイDBシステムとしての高可用性の要求には十二分に応じられる機能を有していることが確認できました。 - XAG Agentが仲介することにより、複雑な管理コマンド(crsctl,srvctl)を駆使せずとも、agctl によってMySQLインスタンスをシンプルに操作できることが利点となります。
- GI未経験のユーザーにはどうしてもハードルになってしまうのは致し方ないところではあります。
一方で、既にOracle RACを運用されているユーザーとってはスキル習熟コストも少なくて済むかもしれません。 - DBとClusterwareの製品サポートを一本化するというメリットもあります。
- 概要レベルになりましたが、構成検討の際の一助となれば幸いです。


